

脑电证据揭秘语言认知差异,解析大脑如何快速 “读懂” 代词
2026-05-15 来源:本站 点击次数:109
大脑如何快速 “读懂” 代词?脑电证据揭秘语言认知差异
引言
当我们读到一个"他"或"她"时,大脑需要在极短时间内判断这个代词指的是谁——这个过程被称为代词消解。它看似自动化,实则涉及复杂的神经认知运算。临床研究发现,中风失语症、阿尔茨海默病和帕金森病患者往往在代词理解上出现明显障碍,这说明代词消解绝非"简单"的语言任务,其神经基础值得深入探究。
那么,大脑究竟依靠什么线索来完成代词消解?性别信息、动词语义、话语焦点——这些不同类型的语言线索是否激活了不同的认知机制?以往研究大多只关注单一因素,比如单独考察 theta 或 gamma 频段振荡与指代加工的关系,缺乏对多种线索驱动机制的系统性对比。
论文概述
上海理工大学有关课题组在《Journal of Neuroscience Methods》上发表了题为“EEG-based neurophysiological indicators in pronoun resolution using feature analysis”的研究论文。该研究通过脑电图(EEG)记录被试在代词消解任务中的神经活动,结合ReliefF特征选择算法和线性判别分析(LDA),系统识别了性别线索、动词偏向和话语焦点三种消解策略对应的神经生理指标。

文章信息
研究方法
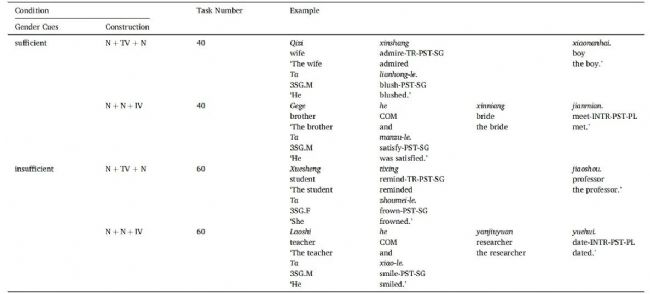
实验材料包含200个中文句对,每对由一个名词句和一个代词句组成。名词句中包含两个潜在的代词先行词,分别来自80个名词的数据库(20个男性偏向词、20个女性偏向词、40个性别中性词)。句子结构分为两类:“名词+及物动词+名词"和"名词+名词+不及物动词”;前者突出动词偏向效应,后者促进话语焦点效应。实验设置了四种条件,通过操控名词-代词的性别一致性来提供充分或不充分的性别线索。
表1 所有实验条件下的示例材料
研究团队招募了20名上海理工大学的右利手学生(14男6女,18-25岁),均为汉语母语者,视力正常且无神经系统疾病史。实验在安静的暗光房间中进行,被试坐在距笔记本电脑屏幕60厘米处,头戴脑电设备,该设备配备14个记录通道,按照国际10-20系统分布,如图1所示。
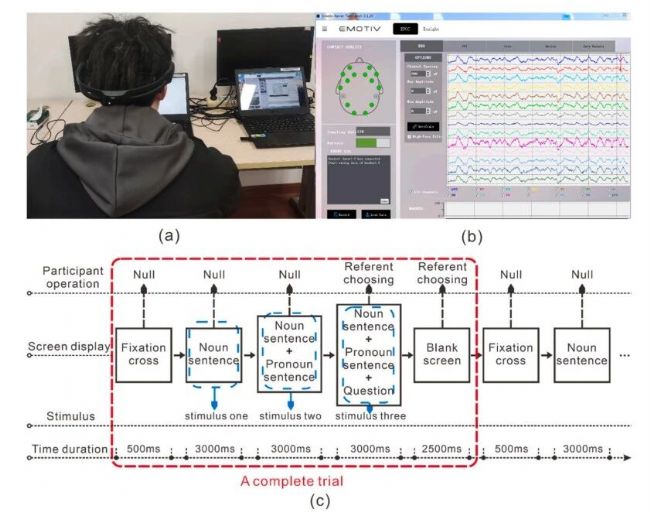
图1 (a) 实验环境(b) 脑电采集软件(c) 代词消歧任务的实验流程
每个试次的流程为:500毫秒注视点、3000毫秒名词句呈现、3000毫秒代词句呈现、3000毫秒指代问题,被试通过按键选择代词所指对象,随后是2500毫秒的试次间隔。整个实验分为5个session,每个session包含40个试次。
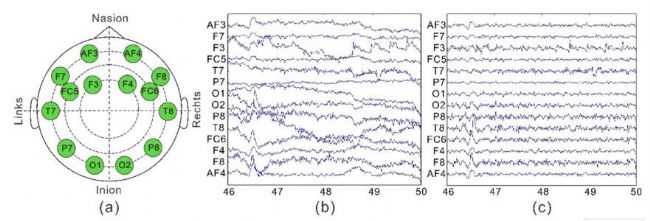
脑电数据采集后,经过4-45 Hz有限脉冲响应滤波器处理以去除运动伪迹。随后进行平均参考计算和基于独立成分分析(ICA)的伪迹去除。从50分钟的记录中提取40分钟的有效数据,每位被试获得200个12秒的脑电片段。
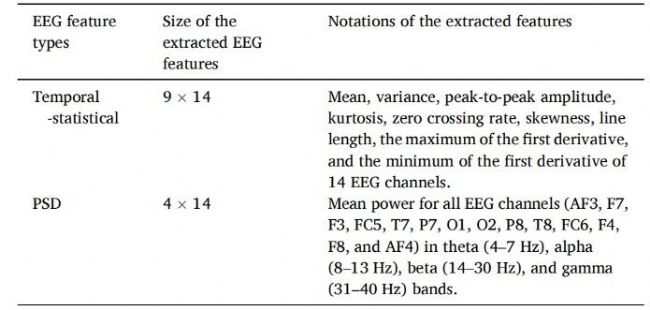
研究对提取的脑电时域、频域特征进行了规整分类,具体特征类型与参数汇总如表 2所示。
表2 提取的脑电特征及其标注汇总
行为数据分析
反应时分析揭示了三种消解策略之间的显著差异。基于性别线索的消解反应时最短(平均748.77毫秒),动词偏向次之(平均903.20毫秒),话语焦点最慢(平均948.92毫秒)。Wilcoxon符号秩检验证实所有配对之间差异显著(p < 0.05),表明性别线索能促进更快速的决策,而动词偏向和话语焦点因其不确定性需要更多加工时间。
脑电特征的统计差异
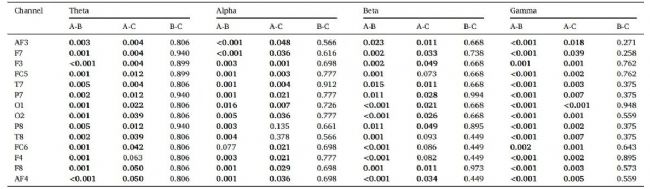
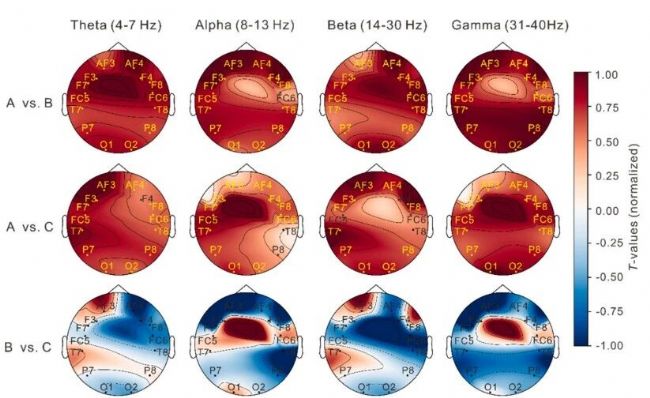
对 56 个 PSD 特征进行双样本 t 检验,各导联、各频段经 FDR 校正后的统计学差异 q 值汇总。研究发现,性别线索条件(标签 A)与动词偏向条件(标签 B)之间几乎在所有通道和频段都存在显著差异。标签A与话语焦点条件(标签C)的对比也呈现广泛的显著差异。然而,标签B与标签C之间未观察到显著差异,说明这两种策略可能共享部分神经加工机制。
表3 基于任务标签、EEG通道和频段(θ波:4–7 Hz,α波:8–13 Hz,β波:14–30 Hz,γ波:31–40 Hz)的双样本t检验,14个EEG通道经错误发现率(FDR)校正(Benjamini-Hochberg法)后的q值
特征贡献分析
研究对比了 CFS、ReliefF、UFSOL、ILFS、DGUFS 五种特征选择模型与 SVM、LDA、KNN 等分类器的组合性能,各组合分类准确率与最优特征维度对比见表 4。进一步单独分析各独立频段及多频段组合的分类效果,不同频段特征集的分类准确率如表 5所示。gamma 波段单独准确率最高,theta+alpha+beta 三频段融合组合表现最优,全频段叠加反而出现冗余、准确率小幅下降。ReliefF结合LDA的最优组合在选取前45%特征时达到48%的分类准确率,20位被试的平均分类准确率为49.08%,显著高于随机水平(33.33%,t = 10.349,p < 0.001)。
表4 特征选择模型和分类器的准确率及最优特征维度
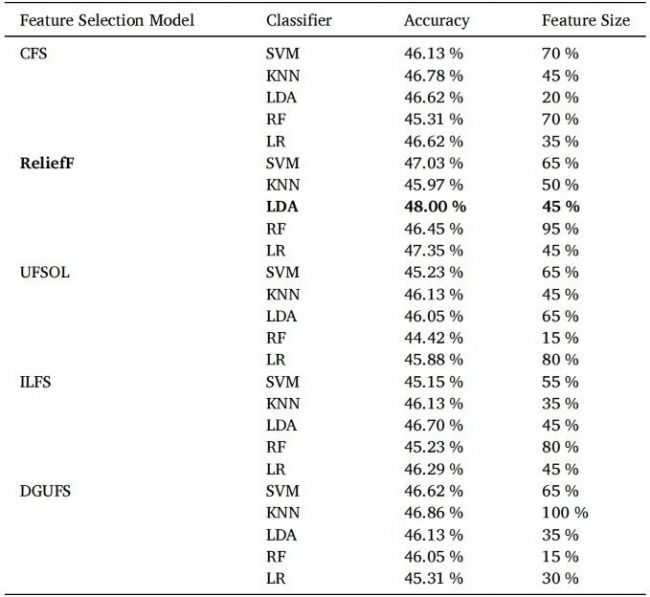
表5 采用ReliefF和LDA的频带特征集准确率

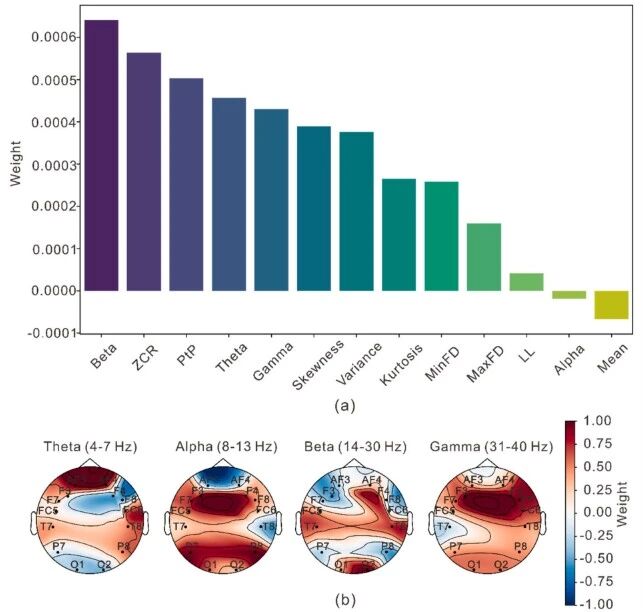
使用ReliefF算法进行特征重要性排序, beta频段特征表现出最高的判别力,其次是过零率(ZCR)和峰峰值(PtP)。theta和gamma频段也有显著贡献。空间分布上,AF3、AF4、FC6、F4、T7、T8和O2通道的贡献最为突出。theta频段在前额区(AF3、AF4)和右颞区(FC6、T8)活动显著,beta频段在枕区(O2)、前额区(AF4)和颞区(T7、T8)表现强烈,gamma频段则在额区(F3、F4)活动明显。
结论与启示
这项研究通过综合特征分析,成功识别出代词消解过程中不同策略对应的脑电神经生理指标。性别线索加工表现出高效的神经机制——在前额和颞区的theta、beta和gamma频段呈现更高的PSD值,反映了直接的信息加工和快速的指代关系确认。这种“特征驱动”的加工模式与动词语义和话语焦点所需的“推理驱动”加工形成鲜明对比,后者涉及更复杂的语义分析和高层次语境整合。
研究结果对计算语言学模型的开发具有启示意义,所识别的神经生理指标可作为语言加工评估的潜在生物标志物,为中风后失语症、阿尔茨海默病等语言障碍的临床诊断和干预提供参考。未来研究可扩大样本量以增强统计效力,开展跨语言对比以验证这些指标的普适性,并探索深度学习方法在脑电特征分类中的应用潜力。
原文信息及链接
Yingyi Qiu, Wenlong Wu, Yinuo Shi, Hongjuan Wei, Hanqing Wang, Ziao Tian, Mengyuan Zhao. EEG-based neurophysiological indicators in pronoun resolution using feature analysis. Journal of Neuroscience Methods, 2025, 419: 110462.
https://doi.org/10.1016/j.jneumeth.2025.110462
研究团队介绍
Yingyi Qiu和Wenlong Wu为共同第一作者,分别来自上海理工大学外语学院和光电信息与计算机工程学院。通讯作者Mengyuan Zhao为上海理工大学外语学院研究人员,研究方向涵盖神经语言学、脑电信号分析与语言认知机制。团队成员还包括来自中国科学院上海微系统与信息技术研究所的ZiAo Tian。该研究得到教育部人文社会科学项目(No. 24YJCZH443)的资助。
关于维拓启创
维拓启创(北京)信息技术有限公司成立于2006年,是一家专注于脑科学、康复工程、人因工程、心理学、体育科学等领域的科研解决方案供应商。公司与国内外多所大学、研究机构、企业长期保持合作关系,致力于将优质的产品、先进的技术和服务带给各个领域的科研工作者,为用户提供有竞争力的方案和服务,协助用户的科研工作,持续提升使用体验。
相关产品

引言
当我们读到一个"他"或"她"时,大脑需要在极短时间内判断这个代词指的是谁——这个过程被称为代词消解。它看似自动化,实则涉及复杂的神经认知运算。临床研究发现,中风失语症、阿尔茨海默病和帕金森病患者往往在代词理解上出现明显障碍,这说明代词消解绝非"简单"的语言任务,其神经基础值得深入探究。
那么,大脑究竟依靠什么线索来完成代词消解?性别信息、动词语义、话语焦点——这些不同类型的语言线索是否激活了不同的认知机制?以往研究大多只关注单一因素,比如单独考察 theta 或 gamma 频段振荡与指代加工的关系,缺乏对多种线索驱动机制的系统性对比。
论文概述
上海理工大学有关课题组在《Journal of Neuroscience Methods》上发表了题为“EEG-based neurophysiological indicators in pronoun resolution using feature analysis”的研究论文。该研究通过脑电图(EEG)记录被试在代词消解任务中的神经活动,结合ReliefF特征选择算法和线性判别分析(LDA),系统识别了性别线索、动词偏向和话语焦点三种消解策略对应的神经生理指标。
文章信息
研究方法
实验材料包含200个中文句对,每对由一个名词句和一个代词句组成。名词句中包含两个潜在的代词先行词,分别来自80个名词的数据库(20个男性偏向词、20个女性偏向词、40个性别中性词)。句子结构分为两类:“名词+及物动词+名词"和"名词+名词+不及物动词”;前者突出动词偏向效应,后者促进话语焦点效应。实验设置了四种条件,通过操控名词-代词的性别一致性来提供充分或不充分的性别线索。
表1 所有实验条件下的示例材料
研究团队招募了20名上海理工大学的右利手学生(14男6女,18-25岁),均为汉语母语者,视力正常且无神经系统疾病史。实验在安静的暗光房间中进行,被试坐在距笔记本电脑屏幕60厘米处,头戴脑电设备,该设备配备14个记录通道,按照国际10-20系统分布,如图1所示。
图1 (a) 实验环境(b) 脑电采集软件(c) 代词消歧任务的实验流程
每个试次的流程为:500毫秒注视点、3000毫秒名词句呈现、3000毫秒代词句呈现、3000毫秒指代问题,被试通过按键选择代词所指对象,随后是2500毫秒的试次间隔。整个实验分为5个session,每个session包含40个试次。
脑电数据采集后,经过4-45 Hz有限脉冲响应滤波器处理以去除运动伪迹。随后进行平均参考计算和基于独立成分分析(ICA)的伪迹去除。从50分钟的记录中提取40分钟的有效数据,每位被试获得200个12秒的脑电片段。
图2 (a) 14个电极的位置(b) 原始脑电图的时间序列(c) 8号参与者在4秒时间区间(46至50秒)内滤波后脑电图的时间序列
研究对提取的脑电时域、频域特征进行了规整分类,具体特征类型与参数汇总如表 2所示。
表2 提取的脑电特征及其标注汇总
研究者从每个通道提取了9个时间-统计特征(均值、方差、峰峰值、峰度、过零率、偏度、线长度、一阶导数最大值和最小值),14个通道共产生126个时域特征。同时通过快速傅里叶变换计算功率谱密度(PSD),分析theta(4-7 Hz)、alpha(8-13 Hz)、beta(14-30 Hz)和gamma(31-40 Hz)四个频段的功率分布,产生56个PSD特征。实验结束后,被试通过问卷标注每次代词消解的决策依据:性别线索(A)、动词偏向(B)或话语焦点(C)。
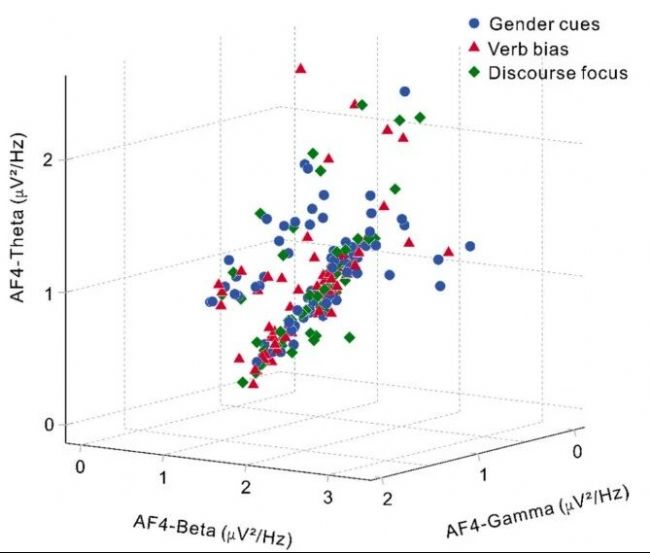
图3 标准化3D散点图
展示参与者#8的AF4通道在θ、β和γ波段的PSD特征,呈现了200个不同标签下的特征向量:(A) 性别线索、(B) 动词偏向、(C) 语篇焦点
研究结果 行为数据分析
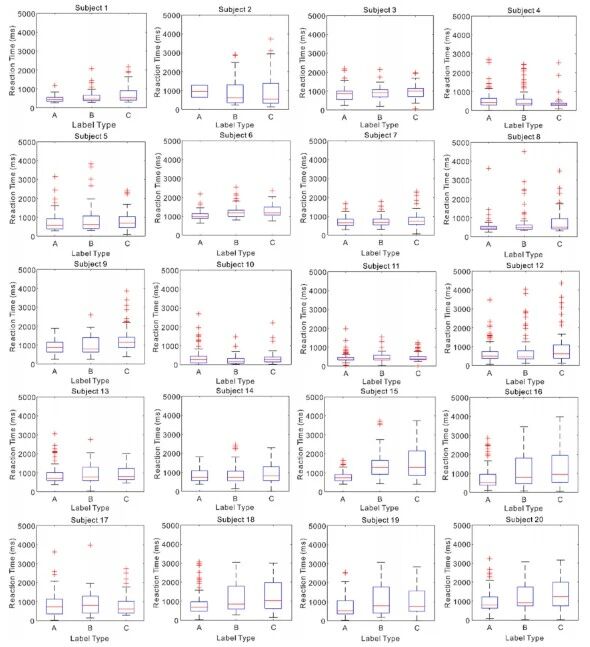
反应时分析揭示了三种消解策略之间的显著差异。基于性别线索的消解反应时最短(平均748.77毫秒),动词偏向次之(平均903.20毫秒),话语焦点最慢(平均948.92毫秒)。Wilcoxon符号秩检验证实所有配对之间差异显著(p < 0.05),表明性别线索能促进更快速的决策,而动词偏向和话语焦点因其不确定性需要更多加工时间。
图4 三名被试在三种任务标签下的反应时间箱线图
脑电特征的统计差异
对 56 个 PSD 特征进行双样本 t 检验,各导联、各频段经 FDR 校正后的统计学差异 q 值汇总。研究发现,性别线索条件(标签 A)与动词偏向条件(标签 B)之间几乎在所有通道和频段都存在显著差异。标签A与话语焦点条件(标签C)的对比也呈现广泛的显著差异。然而,标签B与标签C之间未观察到显著差异,说明这两种策略可能共享部分神经加工机制。
表3 基于任务标签、EEG通道和频段(θ波:4–7 Hz,α波:8–13 Hz,β波:14–30 Hz,γ波:31–40 Hz)的双样本t检验,14个EEG通道经错误发现率(FDR)校正(Benjamini-Hochberg法)后的q值
图5 不同频段下标签A、标签B与标签C对比的t值地形图(θ波:4–7 Hz,α波:8–13 Hz,β波:14–30 Hz,γ波:31–40 Hz)
特征贡献分析
研究对比了 CFS、ReliefF、UFSOL、ILFS、DGUFS 五种特征选择模型与 SVM、LDA、KNN 等分类器的组合性能,各组合分类准确率与最优特征维度对比见表 4。进一步单独分析各独立频段及多频段组合的分类效果,不同频段特征集的分类准确率如表 5所示。gamma 波段单独准确率最高,theta+alpha+beta 三频段融合组合表现最优,全频段叠加反而出现冗余、准确率小幅下降。ReliefF结合LDA的最优组合在选取前45%特征时达到48%的分类准确率,20位被试的平均分类准确率为49.08%,显著高于随机水平(33.33%,t = 10.349,p < 0.001)。
表4 特征选择模型和分类器的准确率及最优特征维度
表5 采用ReliefF和LDA的频带特征集准确率
使用ReliefF算法进行特征重要性排序, beta频段特征表现出最高的判别力,其次是过零率(ZCR)和峰峰值(PtP)。theta和gamma频段也有显著贡献。空间分布上,AF3、AF4、FC6、F4、T7、T8和O2通道的贡献最为突出。theta频段在前额区(AF3、AF4)和右颞区(FC6、T8)活动显著,beta频段在枕区(O2)、前额区(AF4)和颞区(T7、T8)表现强烈,gamma频段则在额区(F3、F4)活动明显。
图6 分类三种代词解析机制的特征重要性分析
(a)基于ReliefF算法的特征集相对权重(b)θ、beta和γ频段内通道特定特征贡献的热图
结论与启示
这项研究通过综合特征分析,成功识别出代词消解过程中不同策略对应的脑电神经生理指标。性别线索加工表现出高效的神经机制——在前额和颞区的theta、beta和gamma频段呈现更高的PSD值,反映了直接的信息加工和快速的指代关系确认。这种“特征驱动”的加工模式与动词语义和话语焦点所需的“推理驱动”加工形成鲜明对比,后者涉及更复杂的语义分析和高层次语境整合。
研究结果对计算语言学模型的开发具有启示意义,所识别的神经生理指标可作为语言加工评估的潜在生物标志物,为中风后失语症、阿尔茨海默病等语言障碍的临床诊断和干预提供参考。未来研究可扩大样本量以增强统计效力,开展跨语言对比以验证这些指标的普适性,并探索深度学习方法在脑电特征分类中的应用潜力。
原文信息及链接
Yingyi Qiu, Wenlong Wu, Yinuo Shi, Hongjuan Wei, Hanqing Wang, Ziao Tian, Mengyuan Zhao. EEG-based neurophysiological indicators in pronoun resolution using feature analysis. Journal of Neuroscience Methods, 2025, 419: 110462.
https://doi.org/10.1016/j.jneumeth.2025.110462
研究团队介绍
Yingyi Qiu和Wenlong Wu为共同第一作者,分别来自上海理工大学外语学院和光电信息与计算机工程学院。通讯作者Mengyuan Zhao为上海理工大学外语学院研究人员,研究方向涵盖神经语言学、脑电信号分析与语言认知机制。团队成员还包括来自中国科学院上海微系统与信息技术研究所的ZiAo Tian。该研究得到教育部人文社会科学项目(No. 24YJCZH443)的资助。
关于维拓启创
维拓启创(北京)信息技术有限公司成立于2006年,是一家专注于脑科学、康复工程、人因工程、心理学、体育科学等领域的科研解决方案供应商。公司与国内外多所大学、研究机构、企业长期保持合作关系,致力于将优质的产品、先进的技术和服务带给各个领域的科研工作者,为用户提供有竞争力的方案和服务,协助用户的科研工作,持续提升使用体验。
相关产品
相关文章
更多 >