

NetMHCⅡphosPan用于预测 HLA-Ⅱ 类抗原呈递磷酸化多肽
2026-05-06 来源:本站 点击次数:436
人类白细胞抗原Ⅱ类分子 (HLA class Ⅱ) 在适应性免疫中的核心功能是呈递抗原肽给 CD4+ T 细胞,调控免疫应答与免疫耐受。磷酸化是一种普遍存在的蛋白质翻译后修饰 (PTM),可以改变蛋白结构与功能,并且磷酸化修饰的抗原肽同样可以被 HLA-Ⅱ 呈递并被 T 细胞识别,在自身免疫病、感染与肿瘤免疫中具有重要作用。
然而,磷酸化 HLA-Ⅱ 配体的精准鉴定与预测面临多重挑战:现有的预测工具(如 NetMHCⅡpan-4.3, MixMHC2pred-1.3)主要针对未修饰肽段,无法准确处理磷酸化修饰;此前的研究尝试利用质谱数据训练模型,但受限于数据质量不佳、噪声大(假阳性高),导致预测效果不理想。
2026年4月,Garcia Alvarez HM等人在 Journal of proteome research 上发表题为 "NetMHCⅡphosPan: A Machine Learning Tool for Predicting HLA Class Ⅱ Antigen Presentation of Phosphorylated Peptides" 的研究论文。该研究基于质谱免疫肽组学数据集,开发了专门用于预测 HLA-Ⅱ 类抗原对磷酸化多肽呈递能力的机器学习工具。研究中质谱数据的磷酸化多肽鉴定使用 PEAKS® Studio 软件的免疫肽组专用工作流即 DeepNovo Peptidome workflow 完成,为后续模型构建提供了高质量的数据基础。该项成果也让 NetMHCⅡphosPan 成为当前研究 HLA-Ⅱ 类分子磷酸化配体呈递的前沿工具,为免疫治疗研发与疫苗设计提供了重要技术支撑。
整体策略与技术方案
首先使用 PEAKS® Studio 的 DeepNovo Peptidome 工作流重新分析公共免疫肽组学数据,将磷酸化设置为可变修饰并以 5% FDR 进行质控,显著提升了磷酸化配体的鉴定数量与质量,构建了覆盖多 HLA 亚型的高质量磷酸化多肽数据集,以便后续模型训练。随后基于 NNAlign_MA 算法,用不同的模型分别进行训练,非修饰肽为 5 倍交叉验证,磷酸化肽为 10 倍交叉验证,所有模型都涵盖了 NetMHCⅡpan-4.3 中的非修饰肽的结合亲和力 (BA) 数据。最后通过内部交叉验证与独立外部数据集验证,对比 NetMHCⅡpan-4.3, MixMHC2pred-1.3 等工具评估模型性能,解析磷酸化肽的结合基序规律。
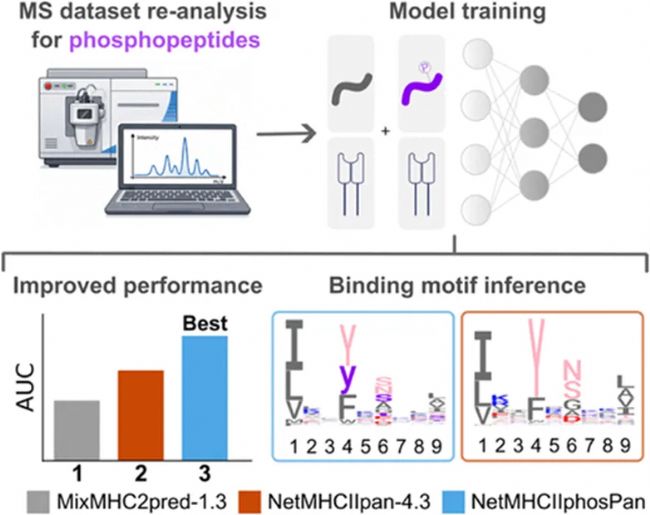
研究结果
1.优化流程可提升磷酸化免疫肽鉴定数量与质量
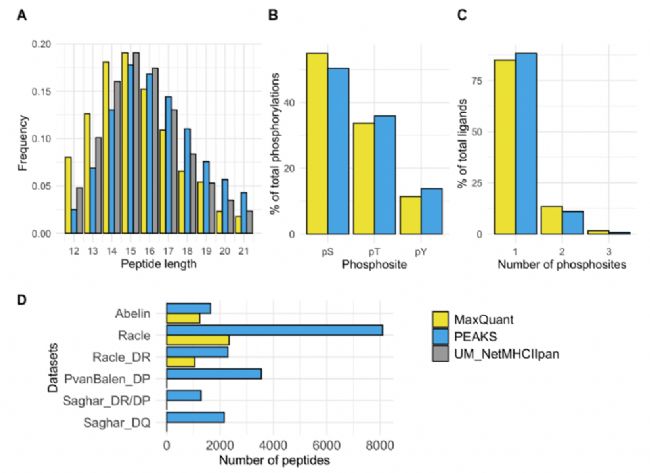
与传统使用 MaxQuant 软件的分析流程相比,PEAKS 鉴定流程在多个公共数据集中将磷酸化多肽的有效鉴定数量提升 33%~246%,同时降低了数据噪声与假阳性,获得了纯度更高、覆盖 HLA-DR/DP/DQ 多亚型的磷酸化配体数据集 (Figure 1)。
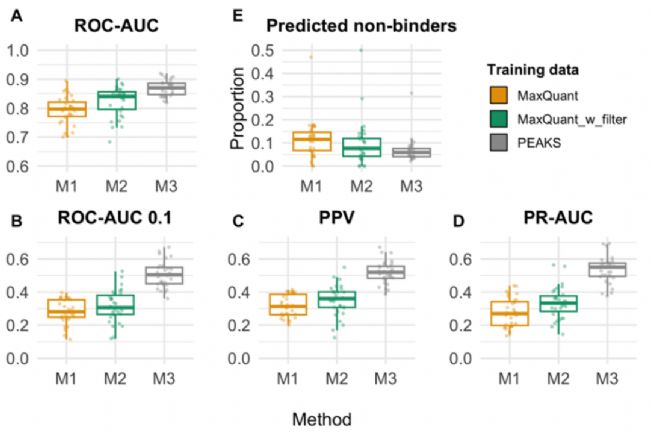
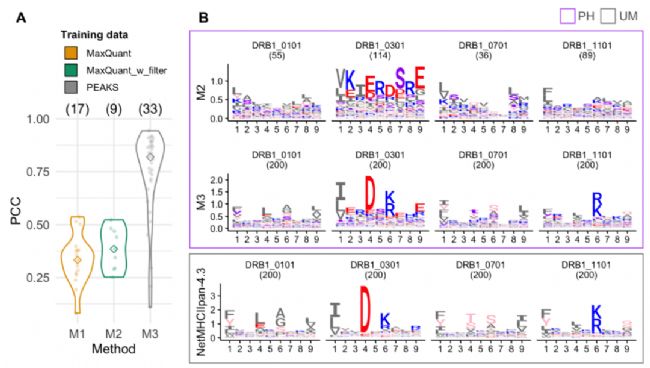
进一步使用 PEAKS 和 MaxQuant 两种软件鉴定的结果分别训练模型后发现,选用 PEAKS 产出的高质量数据训练的模型,预测性能更优,得到的结合基序更清晰,且与未修饰肽的结合基序一致性更高 (Figure 2, Figure 3)。
2.NetMHCⅡphosPan 展现良好预测性能
在此基础上,研究对预测模型进行多轮迭代优化:在初始模型中加入未修饰 HLA 配体数据扩充训练集,对低丰度磷酸化肽进行 10 倍交叉验证,并针对 HLA-DP 分子特有的反向结合模式优化模型结构,显著提升了 HLA-DP, HLA-DQ 亚型的预测精度 (Figure 4)。经多组对比筛选,最终 M6 表现最优异,被选择作为 NetMHCⅡphosPan 的基本模型。
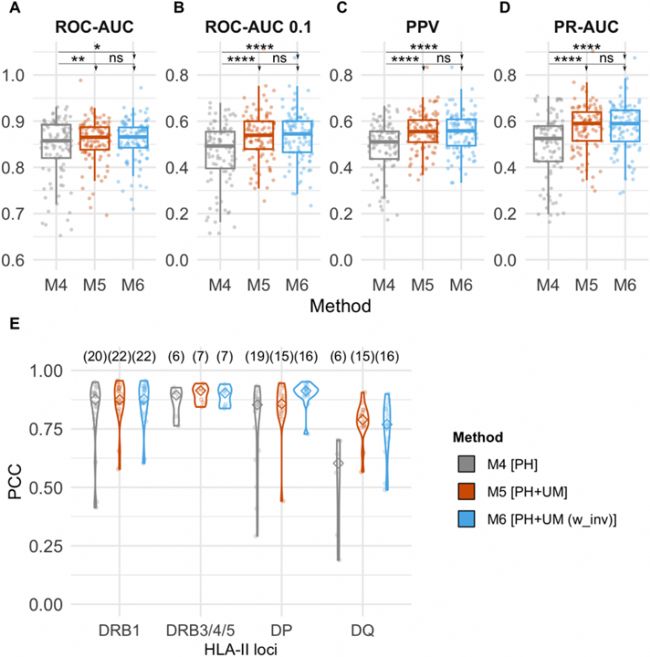
Figure 4. 在训练集中加入未修饰配体并允许肽段反向结合,对仅使用磷酸化配体训练的基础模型的性能提升
随后,研究对 NetMHCⅡphosPan 开展系统性性能验证。在 5 倍交叉验证中,该模型在 ROC-AUC, ROC-AUC 0.1, PR-AUC, PPV 等关键指标上全面优于仅针对未修饰肽开发的 NetMHCⅡpan-4.3 (Figure 5)。
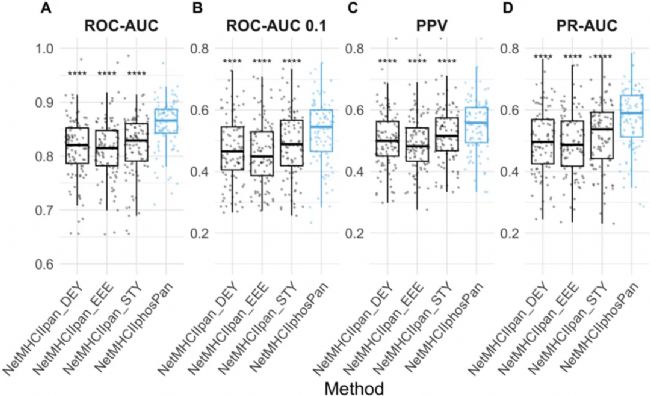
Figure 5. NetMHCⅡphosPan 与 NetMHCⅡpan-4.3 在训练集磷酸化配体上的五折交叉验证性能
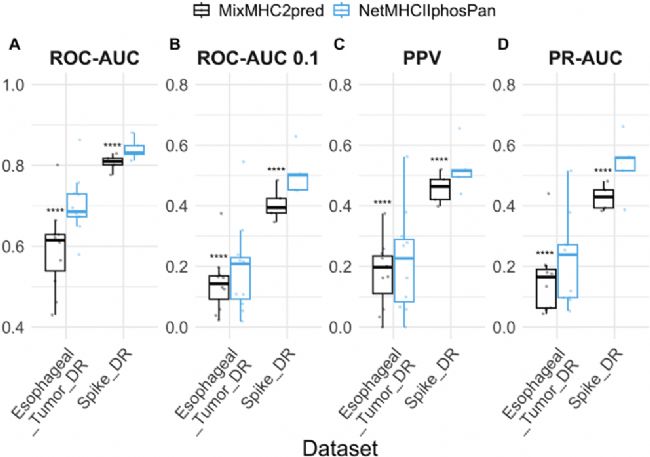
在食管癌组织和新冠刺突蛋白刺激细胞系两套独立外部数据集上,该模型预测效果同样显著优于 MixMHC2pred-1.3 (Figure 8),证明其不仅在训练集上表现优异,还具备更广的适用性与实际应用价值。
3.磷酸化多肽结合基序与未修饰多肽高度一致
此外,研究揭示了磷酸化多肽与 HLA-Ⅱ 分子的结合机制。序列识别图分析直观展示了 HLA-Ⅱ 类分子对磷酸化多肽的等位基因特异性结合偏好,与未修饰多肽的结合规律基本吻合 (Figure 6)。
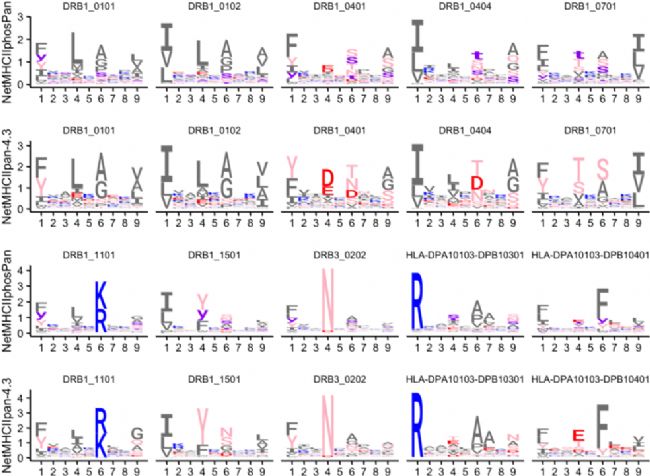
Figure 6. 未修饰和磷酸化肽的 HLA-Ⅱ 结合偏好的序列序列标识图
磷酸位点在 9-mer 结合核心内无明显分布偏好,仅在 P1, P4, P6, P9 经典锚定位点表现出特征性富集或排斥,而这种偏好本质上由未修饰丝氨酸、苏氨酸、酪氨酸的天然结合特性决定 (Figure 7)。
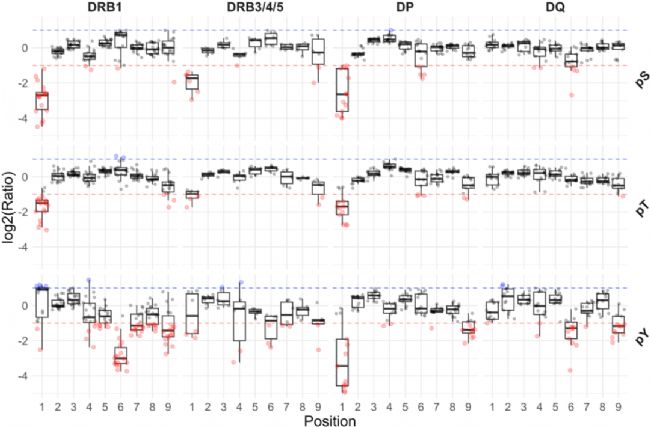
Figure 7. 按等位基因(列)和磷酸化类型(行)区分, NetMHCⅡphosPan 预测的 9 聚体结合核心区内磷酸化位点的富集与缺失情况
4.磷酸化对结合核心影响有限
将磷酸化多肽去磷酸化后,91% 的磷酸化多肽结合核心保持不变,仅有 9% 的多肽出现结合核心偏移;同时,去除磷酸基团后,多肽与 HLA-Ⅱ 分子的结合强度仅出现小幅下降,说明磷酸化修饰并未从根本上改变 HLA-Ⅱ 类分子识别抗原的核心模式。
总结
本研究借助 PEAKS® Studio 软件优化了免疫肽组学数据分析流程,获得了高质量、广覆盖的 HLA-Ⅱ 类磷酸化配体数据集,并成功构建了首个泛特异性 HLA-Ⅱ 类磷酸化多肽抗原呈递预测工具 NetMHCⅡphosPan。该模型性能显著优于现有工具,能够准确预测磷酸化肽与 HLA-DR, HLA-DP, HLA-DQ 分子的结合能力,同时揭示磷酸化肽的 HLA-Ⅱ 类分子结合规律与未修饰肽高度一致;磷酸化主要通过影响锚定位点偏好调控结合强度,并不会改变核心识别模式。NetMHCⅡphosPan 可为肿瘤疫苗设计、免疫治疗靶点筛选、自身免疫抗原鉴定等研究提供关键支撑,也为其他翻译后修饰的 HLA 呈递研究提供了可借鉴的策略。
原文链接:https://pubmed.ncbi.nlm.nih.gov/41994856/
PEAKS® Studio 软件可以最大限度的解析出谱图中包含的鉴定信息和准确的定量结果,兼容 DDA、DIA 和靶向数据分析功能,与先进的仪器结合,可以实现更加完整的一站式蛋白质组学研究。如果需要进一步了解软件的功能与应用,您可以通过文末的联系方式预约一对一技术介绍。
作为生物信息学的领军企业,BSI专注于蛋白质组学和生物药领域,通过机器学习和先进算法提供世界领先的质谱数据分析软件和蛋白质组学服务解决方案,以推进生物学研究和药物发现。我们通过基于AI的计算方案,为您提供对蛋白质组学、基因组学和医学的卓越洞见。旗下著名的PEAKS®️系列软件在全世界拥有数千家学术和工业用户,包括:PEAKS®️ Studio,PEAKS®️ Online,PEAKS®️ GlycanFinder, PEAKS®️ AB,ProteoformXTM,DeepImmu®️ 免疫肽组发现服务和抗体综合表征服务等。
然而,磷酸化 HLA-Ⅱ 配体的精准鉴定与预测面临多重挑战:现有的预测工具(如 NetMHCⅡpan-4.3, MixMHC2pred-1.3)主要针对未修饰肽段,无法准确处理磷酸化修饰;此前的研究尝试利用质谱数据训练模型,但受限于数据质量不佳、噪声大(假阳性高),导致预测效果不理想。
2026年4月,Garcia Alvarez HM等人在 Journal of proteome research 上发表题为 "NetMHCⅡphosPan: A Machine Learning Tool for Predicting HLA Class Ⅱ Antigen Presentation of Phosphorylated Peptides" 的研究论文。该研究基于质谱免疫肽组学数据集,开发了专门用于预测 HLA-Ⅱ 类抗原对磷酸化多肽呈递能力的机器学习工具。研究中质谱数据的磷酸化多肽鉴定使用 PEAKS® Studio 软件的免疫肽组专用工作流即 DeepNovo Peptidome workflow 完成,为后续模型构建提供了高质量的数据基础。该项成果也让 NetMHCⅡphosPan 成为当前研究 HLA-Ⅱ 类分子磷酸化配体呈递的前沿工具,为免疫治疗研发与疫苗设计提供了重要技术支撑。
整体策略与技术方案
首先使用 PEAKS® Studio 的 DeepNovo Peptidome 工作流重新分析公共免疫肽组学数据,将磷酸化设置为可变修饰并以 5% FDR 进行质控,显著提升了磷酸化配体的鉴定数量与质量,构建了覆盖多 HLA 亚型的高质量磷酸化多肽数据集,以便后续模型训练。随后基于 NNAlign_MA 算法,用不同的模型分别进行训练,非修饰肽为 5 倍交叉验证,磷酸化肽为 10 倍交叉验证,所有模型都涵盖了 NetMHCⅡpan-4.3 中的非修饰肽的结合亲和力 (BA) 数据。最后通过内部交叉验证与独立外部数据集验证,对比 NetMHCⅡpan-4.3, MixMHC2pred-1.3 等工具评估模型性能,解析磷酸化肽的结合基序规律。
1.优化流程可提升磷酸化免疫肽鉴定数量与质量
与传统使用 MaxQuant 软件的分析流程相比,PEAKS 鉴定流程在多个公共数据集中将磷酸化多肽的有效鉴定数量提升 33%~246%,同时降低了数据噪声与假阳性,获得了纯度更高、覆盖 HLA-DR/DP/DQ 多亚型的磷酸化配体数据集 (Figure 1)。
Figure 1. 基于 MaxQuant 与 PEAKS 软件鉴定的磷酸化配体数据集概览
进一步使用 PEAKS 和 MaxQuant 两种软件鉴定的结果分别训练模型后发现,选用 PEAKS 产出的高质量数据训练的模型,预测性能更优,得到的结合基序更清晰,且与未修饰肽的结合基序一致性更高 (Figure 2, Figure 3)。
Figure 2. 基于 MaxQuant 与 PEAKS 鉴定的磷酸化配体所训练模型的五折交叉验证性能
Figure 3. 交叉验证中肽段数量≥30 的 HLA-Ⅱ 分子,其未修饰配体与磷酸化配体结合基序的一致性
2.NetMHCⅡphosPan 展现良好预测性能
在此基础上,研究对预测模型进行多轮迭代优化:在初始模型中加入未修饰 HLA 配体数据扩充训练集,对低丰度磷酸化肽进行 10 倍交叉验证,并针对 HLA-DP 分子特有的反向结合模式优化模型结构,显著提升了 HLA-DP, HLA-DQ 亚型的预测精度 (Figure 4)。经多组对比筛选,最终 M6 表现最优异,被选择作为 NetMHCⅡphosPan 的基本模型。
Figure 4. 在训练集中加入未修饰配体并允许肽段反向结合,对仅使用磷酸化配体训练的基础模型的性能提升
随后,研究对 NetMHCⅡphosPan 开展系统性性能验证。在 5 倍交叉验证中,该模型在 ROC-AUC, ROC-AUC 0.1, PR-AUC, PPV 等关键指标上全面优于仅针对未修饰肽开发的 NetMHCⅡpan-4.3 (Figure 5)。
Figure 5. NetMHCⅡphosPan 与 NetMHCⅡpan-4.3 在训练集磷酸化配体上的五折交叉验证性能
在食管癌组织和新冠刺突蛋白刺激细胞系两套独立外部数据集上,该模型预测效果同样显著优于 MixMHC2pred-1.3 (Figure 8),证明其不仅在训练集上表现优异,还具备更广的适用性与实际应用价值。
Figure 8. NetMHCⅡphosPan 和 MixMHC2pred-1.3 在两个涵盖 HLA-DR 等位基因的磷酸配体外部验证数据集上的性能
3.磷酸化多肽结合基序与未修饰多肽高度一致
此外,研究揭示了磷酸化多肽与 HLA-Ⅱ 分子的结合机制。序列识别图分析直观展示了 HLA-Ⅱ 类分子对磷酸化多肽的等位基因特异性结合偏好,与未修饰多肽的结合规律基本吻合 (Figure 6)。
Figure 6. 未修饰和磷酸化肽的 HLA-Ⅱ 结合偏好的序列序列标识图
磷酸位点在 9-mer 结合核心内无明显分布偏好,仅在 P1, P4, P6, P9 经典锚定位点表现出特征性富集或排斥,而这种偏好本质上由未修饰丝氨酸、苏氨酸、酪氨酸的天然结合特性决定 (Figure 7)。
Figure 7. 按等位基因(列)和磷酸化类型(行)区分, NetMHCⅡphosPan 预测的 9 聚体结合核心区内磷酸化位点的富集与缺失情况
4.磷酸化对结合核心影响有限
将磷酸化多肽去磷酸化后,91% 的磷酸化多肽结合核心保持不变,仅有 9% 的多肽出现结合核心偏移;同时,去除磷酸基团后,多肽与 HLA-Ⅱ 分子的结合强度仅出现小幅下降,说明磷酸化修饰并未从根本上改变 HLA-Ⅱ 类分子识别抗原的核心模式。
总结
本研究借助 PEAKS® Studio 软件优化了免疫肽组学数据分析流程,获得了高质量、广覆盖的 HLA-Ⅱ 类磷酸化配体数据集,并成功构建了首个泛特异性 HLA-Ⅱ 类磷酸化多肽抗原呈递预测工具 NetMHCⅡphosPan。该模型性能显著优于现有工具,能够准确预测磷酸化肽与 HLA-DR, HLA-DP, HLA-DQ 分子的结合能力,同时揭示磷酸化肽的 HLA-Ⅱ 类分子结合规律与未修饰肽高度一致;磷酸化主要通过影响锚定位点偏好调控结合强度,并不会改变核心识别模式。NetMHCⅡphosPan 可为肿瘤疫苗设计、免疫治疗靶点筛选、自身免疫抗原鉴定等研究提供关键支撑,也为其他翻译后修饰的 HLA 呈递研究提供了可借鉴的策略。
原文链接:https://pubmed.ncbi.nlm.nih.gov/41994856/
PEAKS® Studio 软件可以最大限度的解析出谱图中包含的鉴定信息和准确的定量结果,兼容 DDA、DIA 和靶向数据分析功能,与先进的仪器结合,可以实现更加完整的一站式蛋白质组学研究。如果需要进一步了解软件的功能与应用,您可以通过文末的联系方式预约一对一技术介绍。
作为生物信息学的领军企业,BSI专注于蛋白质组学和生物药领域,通过机器学习和先进算法提供世界领先的质谱数据分析软件和蛋白质组学服务解决方案,以推进生物学研究和药物发现。我们通过基于AI的计算方案,为您提供对蛋白质组学、基因组学和医学的卓越洞见。旗下著名的PEAKS®️系列软件在全世界拥有数千家学术和工业用户,包括:PEAKS®️ Studio,PEAKS®️ Online,PEAKS®️ GlycanFinder, PEAKS®️ AB,ProteoformXTM,DeepImmu®️ 免疫肽组发现服务和抗体综合表征服务等。
相关文章
更多 >