

AI驱动精准肿瘤学突破:MUSK模型助力医学研究
2025-05-28 来源:本站 点击次数:955在医学领域,精准诊断和治疗决策一直是医生和患者关注的焦点。然而,面对海量的多模态数据,传统方法往往力不从心。人工智能(AI)技术的崛起,正为这一难题带来革命性解决方案。本期文章聚焦于新的研究成果——MUSK模型,通过整合病理图像和临床文本数据,不仅实现了跨模态检索、视觉问答等复杂任务,还在分子标志物预测、癌症预后和免疫治疗反应预测中展现了卓越性能。MUSK的出现,标志着AI在精准肿瘤学领域的应用迈出了关键一步。通过本文,您将深入了解AI如何改变医学的未来,以及它如何为患者带来更精准、更个性化的治疗选择。
一. 研究背景
临床决策依赖多模态数据,如临床记录和病理特征,但现有方法在整合这些数据方面存在局限。人工智能(AI)在整合多模态数据方面潜力巨大,但高质量标注数据集稀缺,阻碍了模型发展。基础模型通过大规模预训练,可在无需额外训练的情况下应用于多种任务,为医学AI开辟了新方向。然而,现有视觉-语言基础模型在病理学领域面临数据规模不足和任务复杂度有限的挑战。
为此,本研究提出基于多模态统一掩码建模变换器(MUSK)的视觉-语言基础模型。MUSK利用大规模未标注病理图像和文本数据进行预训练,并进一步对齐图像-文本对特征,旨在解决现有模型的局限性。通过广泛任务评估,MUSK在跨模态检索、视觉问答、图像分类、分子标志物预测及临床结果预测中展现了卓越性能,为精准肿瘤学和多模态AI应用提供了新工具。
二. 文章详情
文章题目:A vision–language foundation model for precision oncology
中文题目:用于精准肿瘤学的视觉-语言基础模型
发表时间:2025.02
期刊名称:Nature
影响因子:50.5
DOI:10.1038/s41586-024-08378-w
三. 研究结果
1. MUSK模型预训练
本研究开发了基于多模态Transformer架构的视觉-语言基础模型,作为网络骨干。模型预训练分为两个连续阶段。首先,MUSK在5000万张病理图像和10亿个病理相关文本标记上进行预训练。这些图像来源于11,577名患者的约33,000张全切片组织病理学扫描结果,涵盖了33种肿瘤类型。借鉴BEiT3架构,MUSK模型由共享的自注意力模块以及针对视觉和语言输入的独立专家模块组成;预训练通过掩码建模实现。其次,MUSK在来自QUILT-1M模型的一百万张图像-文本对上进行了预训练,采用对比学习方法以实现多模态对齐。
 Fig1. 数据策划,模型开发和评估
Fig1. 数据策划,模型开发和评估2. MUSK在跨模态任务中的卓越表现
MUSK在跨模态检索和视觉问答(VQA)任务中展现了强大的能力。通过统一掩码建模技术,MUSK在无需额外训练的情况下实现了零样本跨模态检索,在BookSet和PathMMU数据集上显著优于其他基础模型,例如在PathMMU数据集上比第二好的模型(CONCH)高出7.1%。同时,MUSK在视觉问答任务中也表现出色,在PathVQA数据集上的准确率达到73.2%,超越了专门为VQA设计的K-Path VQA模型(准确率:68.9%)。这些结果表明,MUSK能够有效对齐视觉和语言特征,为跨模态任务提供了高效且通用的解决方案。
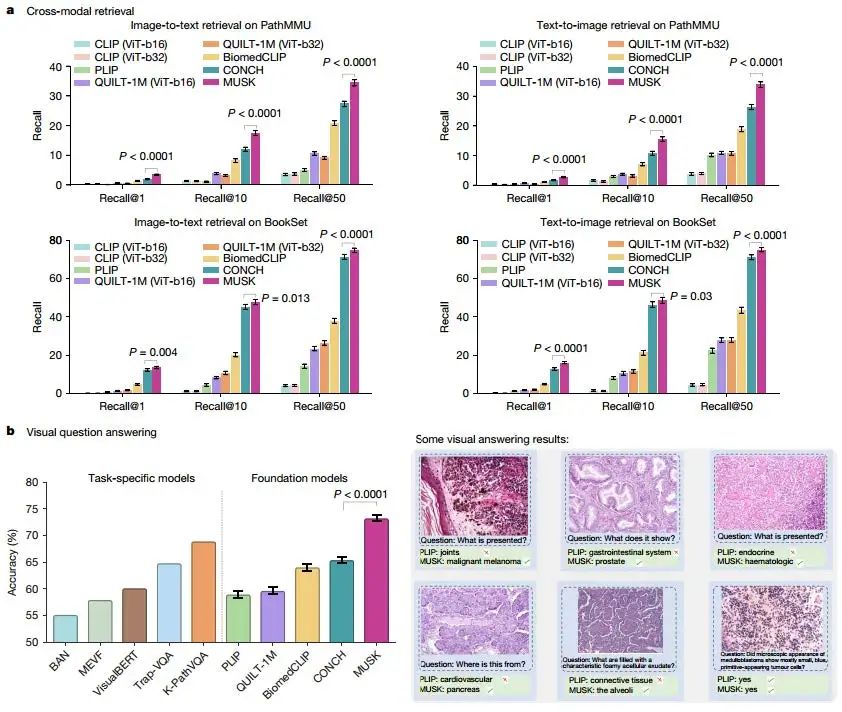 Fig2. 跨模式检索和VQA
Fig2. 跨模式检索和VQA3. 图像检索与分类
MUSK不仅在跨模态任务中表现优异,还可以作为独立的图像编码器用于图像检索和分类任务。在零样本和少样本图像分类中,MUSK在多个基准数据集上均超越了其他基础模型。例如,在十样本图像分类中,MUSK在12个数据集中的10个上表现最佳。此外,MUSK在监督图像分类中的平均准确率达到88.2%,显著优于其他模型。这些结果证明了MUSK在病理图像分类中的高效性和稳健性。
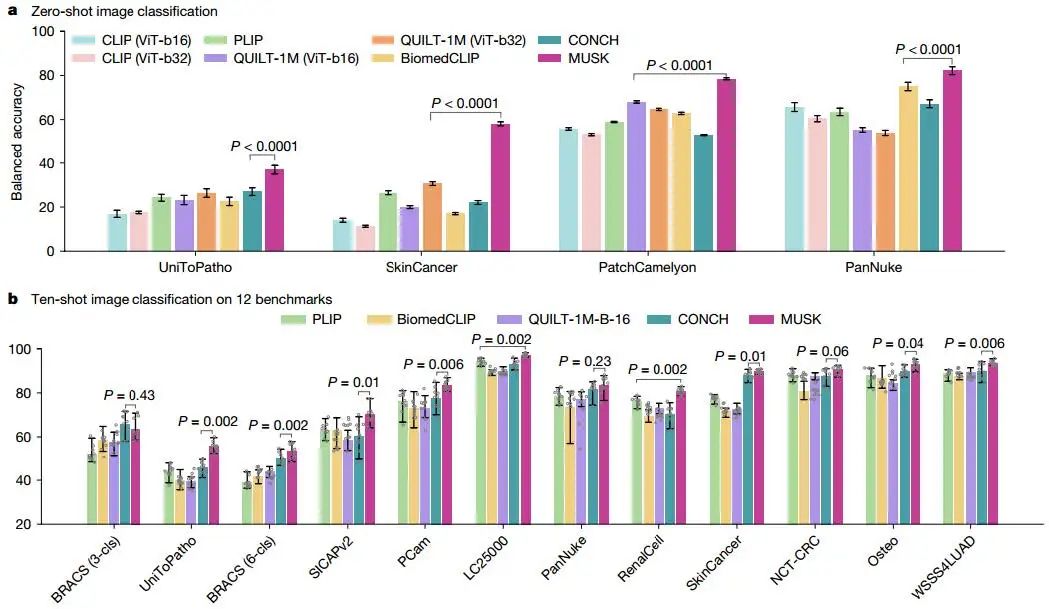 Fig3. 补丁级图像分类
Fig3. 补丁级图像分类4. 分子生物标志物预测
MUSK在从病理图像中预测分子生物标志物方面展现了卓越性能。在乳腺癌受体状态和脑肿瘤IDH突变状态的预测任务中,MUSK的AUC值显著高于其他病理学基础模型。例如,在预测HER2状态时,MUSK的AUC为0.826,优于GigaPath(0.786)和CONCH(0.771)。这表明MUSK能够为精准肿瘤学提供有价值的分子标志物预测工具。
5. 黑色素瘤复发预测
MUSK在预测黑色素瘤复发方面表现出色。基于VisioMel数据集,MUSK在预测5年复发的AUC达到0.833,显著优于其他视觉-语言基础模型。通过结合临床报告和病理图像的多模态信息,MUSK进一步提高了预测准确性。此外,MUSK在90%敏感性阈值下的特异性显著高于其他模型,可能帮助更多患者避免不必要的辅助治疗。
6. 泛癌症预后预测
MUSK在泛癌症预后预测中展现了广泛的应用潜力。基于TCGA数据集的16种癌症类型,MUSK的平均c-index为0.747,显著优于临床风险因素和其他基础模型。例如,在肾细胞癌中,MUSK的c-index达到0.887。通过Kaplan-Meier分析,MUSK能够显著分层低风险和高风险患者,为个性化治疗提供了重要依据。
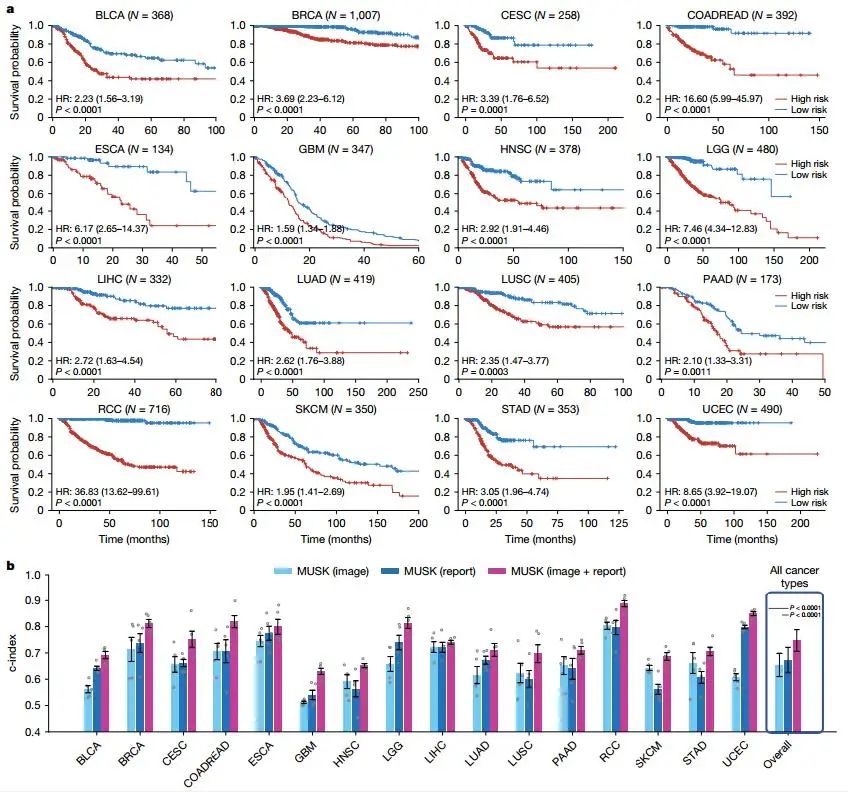 Fig4. 16种癌症类型的预后预测
Fig4. 16种癌症类型的预后预测7. 免疫治疗反应预测
MUSK在预测免疫治疗反应和结果方面表现优异。在晚期非小细胞肺癌和胃食管癌患者中,MUSK的AUC和c-index均显著优于现有生物标志物和其他基础模型。例如,在预测NSCLC患者PFS时,MUSK的c-index为0.705,优于肿瘤PD-L1表达的0.574。通过多模态数据整合,MUSK能够识别可能从免疫治疗中受益的患者,为临床决策提供了有力支持。
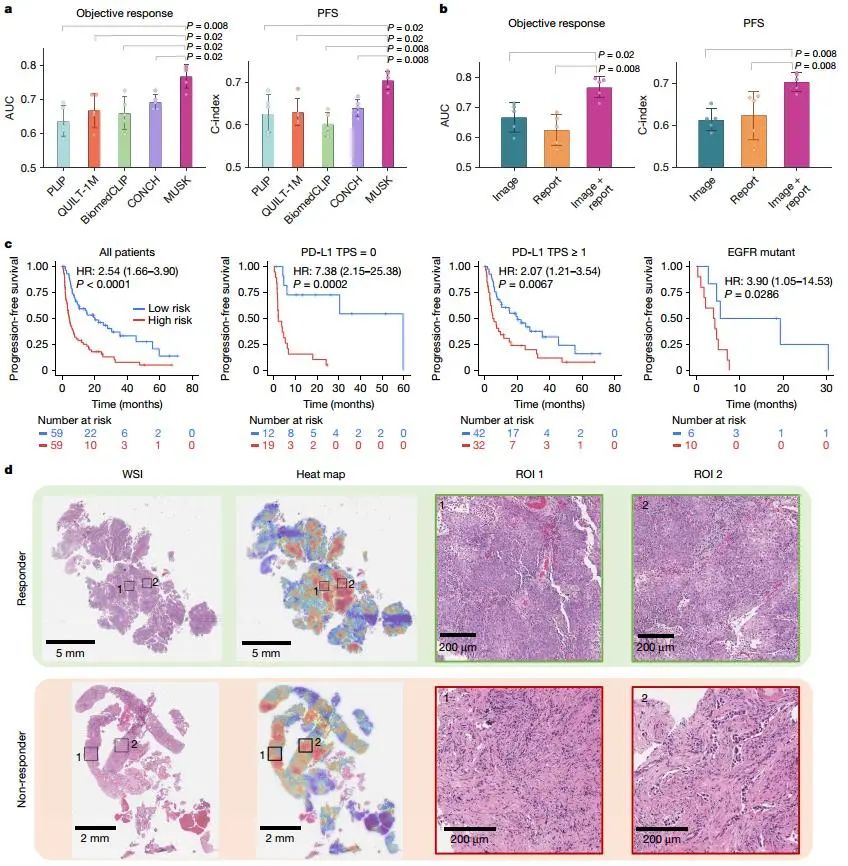 Fig5. 肺癌免疫治疗反应预测
Fig5. 肺癌免疫治疗反应预测四. 主要结论
本研究开发了一种名为“多模态统一掩码建模变换器”(MUSK)的视觉-语言基础模型,旨在利用大规模、未标注、未配对的图像和文本数据。MUSK通过统一掩码建模技术,预训练了来自11,577名患者的5000万张病理图像和10亿个病理相关文本标记。此外,它还进一步预训练了100万张病理图像-文本对,以高效对齐视觉和语言特征。在无需或仅需少量额外训练的情况下,MUSK在23个图像块级别和切片级别的基准测试中展现了卓越性能,涵盖图像到文本和文本到图像的检索、视觉问答、图像分类以及分子生物标志物预测等任务。
此外,MUSK在结果预测方面也表现出色,包括黑色素瘤复发预测、泛癌预后预测以及肺癌和胃食管癌的免疫治疗反应预测。MUSK成功整合了病理图像和临床报告中的互补信息,有望提高癌症诊断的准确性和治疗的精准性。
参考文献
Xiang, Jinxi et al. “A vision-language foundation model for precision oncology.” Nature vol. 638,8051 (2025): 769-778.